Zrobiłem sobie wersję na instrukcji do stringów z SSE 4.2 (cmpistrm).
Na Ryzenie 3900X mam 19.7 GB/s. Zakładając, że działa mi dual-channel (według dmidecode oba są aktywne), powinienem mieć teoretycznie 47 GB/s.
Wygląda na to, że te rozkazy do stringów to trochę lepiocha i nie są w stanie wysycić kontrolera pamięci.
Sprawdziłem perfem, że wykonuje się 2.5 instrukcji/cykl, co mniej więcej pokrywa się z przepustowością pcimpstrm według tablic. Zrobiłem też wersję z wymuszonym unrollingiem. Nie poprawiło wyniku praktycznie wcale.
Przy okazji ciekawostka. Dostęp do rozkazów SSE/AVX w Rust można uzyskać poprzez wbudowane intrinsici, których można używać tylko w bloku unsafe.
Rust w tym trybie jest po prostu naszpikowany pułapkami niczym pole minowe. Kompilator nie weryfikuje nawet, czy podczas budowania binarki zostało włączone wsparcie dla SSE/AVX. Z tej perspektywy jest to mniej bezpieczne niż gcc/clang, które wymagają przynajmniej przekazania flagi -msse*, -mavx*, etc.
W pierwszej wersji kodu nie podałem żadnych dodatkowych parametrów do rustc i pozornie wszystko działało.
Dopiero przy pierwszym pomiarze wydajności zauważyłem, że rustc nie generuje w trybie release gołych rozkazów, tylko wywołuje funkcje:
Wygląda to tylko i wyłącznie na zepsuty inlining, bo funkcje nie robią nic ciekawego:
Obecność tych calli obniżała wydajność o kilkadziesiąt procent i byłaby bardzo trudna do wykrycia bez spojrzenia na kod w profilerze.
Finalnie udało mi się zmusić rustc do inline’owania po przekazaniu dodatkowych flag włączających wsparcie SSE 4.2 i popcnt.
To jest ciekawe wielowymiarowo. Jest tu tyle tajemnic do rozwiązania.
callq jest jakaś formą obsługi generycznego kodu?
jeszcze się okaże, że wasm z instrukcjami wektorowymi jest wydajniejszy
Wydaje mi się, że małe pętle z pobieraniem dużej ilości danych z pamięci są słabe. Trzeba czymś zagospodarować 200 taktów w oczekiwaniu na dane które nie zdążyły przyjść do cache
Odnoszę wrażenie, że twórcy krzemu nie lubili SSE. Pewnie chcieliby założyć na to jakąś abstrakcję. Coś jak w Cray.
Rozkaz callq to zwykłe wywołanie funkcji. W GNUjowej składni asemblera sufiks ‘q’ oznacza 64-bitowy argument.
Odnośnie czekania na dane z pamięci - taki był w sumie mój cel. Chciałem sprawdzić, czy osiągnę tą instrukcją teoretyczną przepustowość kontrolera pamięci. Nie udało się.
W tym przypadku podmiana dzieje się podczas kompilacji. Po przekazaniu flagi do kompilatora rozkaz SSE jest inline’owany w miejscu wywołania i call znika całkowicie.
Nawiasem mówiąc, istnieje taka sztuczka optymalizacyjna do podmiany w runtime funkcji na wersję specjalizowaną pod konkretny procesor.
Wywołania funkcji są robione poprzez wskaźnik, który początkowo wskazuje na kawałek kodu który wykrywa procesor i patchuje ten wskaźnik (żeby kolejne wywołania były szybsze).
Tak samo działa też lazy binding funkcji importowanych z ELFowych bibliotek dynamicznych.
Tylko automatyczne generowanie takich fragmentów jak widać się nie sprawdza. Lepsze wydaje się oznaczanie jaki fragment algorytmu wygenerować w różnych wersjach.

Zrobiłem sobie wersję na instrukcji do stringów z SSE 4.2 (cmpistrm).
Na Ryzenie 3900X mam 19.7 GB/s. Zakładając, że działa mi dual-channel (według dmidecode oba są aktywne), powinienem mieć teoretycznie 47 GB/s.
Wygląda na to, że te rozkazy do stringów to trochę lepiocha i nie są w stanie wysycić kontrolera pamięci.
Sprawdziłem perfem, że wykonuje się 2.5 instrukcji/cykl, co mniej więcej pokrywa się z przepustowością pcimpstrm według tablic. Zrobiłem też wersję z wymuszonym unrollingiem. Nie poprawiło wyniku praktycznie wcale.
Przy okazji ciekawostka. Dostęp do rozkazów SSE/AVX w Rust można uzyskać poprzez wbudowane intrinsici, których można używać tylko w bloku

unsafe.Rust w tym trybie jest po prostu naszpikowany pułapkami niczym pole minowe. Kompilator nie weryfikuje nawet, czy podczas budowania binarki zostało włączone wsparcie dla SSE/AVX. Z tej perspektywy jest to mniej bezpieczne niż gcc/clang, które wymagają przynajmniej przekazania flagi
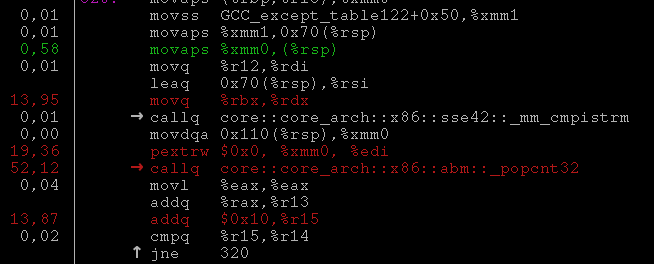
-msse*,-mavx*, etc.W pierwszej wersji kodu nie podałem żadnych dodatkowych parametrów do rustc i pozornie wszystko działało. Dopiero przy pierwszym pomiarze wydajności zauważyłem, że rustc nie generuje w trybie release gołych rozkazów, tylko wywołuje funkcje:
Wygląda to tylko i wyłącznie na zepsuty inlining, bo funkcje nie robią nic ciekawego:
Obecność tych calli obniżała wydajność o kilkadziesiąt procent i byłaby bardzo trudna do wykrycia bez spojrzenia na kod w profilerze.
Finalnie udało mi się zmusić rustc do inline’owania po przekazaniu dodatkowych flag włączających wsparcie SSE 4.2 i popcnt.
To jest ciekawe wielowymiarowo. Jest tu tyle tajemnic do rozwiązania.
Rozkaz callq to zwykłe wywołanie funkcji. W GNUjowej składni asemblera sufiks ‘q’ oznacza 64-bitowy argument.
Odnośnie czekania na dane z pamięci - taki był w sumie mój cel. Chciałem sprawdzić, czy osiągnę tą instrukcją teoretyczną przepustowość kontrolera pamięci. Nie udało się.
Wiem, tylko myślałem, że podmieniają adres funkcji w zależności od obsługiwanych instrukcji. Skoro to znika po wymuszeniu obsługi tych instrukcji.
W tym przypadku podmiana dzieje się podczas kompilacji. Po przekazaniu flagi do kompilatora rozkaz SSE jest inline’owany w miejscu wywołania i call znika całkowicie.
Nawiasem mówiąc, istnieje taka sztuczka optymalizacyjna do podmiany w runtime funkcji na wersję specjalizowaną pod konkretny procesor.
Wywołania funkcji są robione poprzez wskaźnik, który początkowo wskazuje na kawałek kodu który wykrywa procesor i patchuje ten wskaźnik (żeby kolejne wywołania były szybsze).
Tak samo działa też lazy binding funkcji importowanych z ELFowych bibliotek dynamicznych.
Tylko automatyczne generowanie takich fragmentów jak widać się nie sprawdza. Lepsze wydaje się oznaczanie jaki fragment algorytmu wygenerować w różnych wersjach.